

RomiやLOVOT、NICOBOなど、AIを搭載したコミュニケーションロボットやガジェットが続々と登場しています。こうした流れに興味があり、最近話題の「ポケとも」と、しばらくコミュニケーションを楽しんでいました。
「ポケとも」には、ぬいぐるみ型デバイスとスマホアプリの2種類があり、どちらも同じ仕組みで動作します。今回私が試したのはスマホアプリ版です。

名前は「大五郎(だいごろう)」にしました。
俺とおまえと、大五郎〜
ポケともには、端末内で動く「ローカルLLM」と、クラウド上の強力な「クラウドLLM」を組み合わせるという工夫が凝らされています。こちらが話しかけてから回答が返ってくるまでの間、ローカルLLMが「ふむふむ」「えーっと」と相槌を打って、間を持たせてくれます。
会話していて「なるほど、こうやって自然な会話感を演出しているのか」と感心する一方で、ふと一つの疑問が浮かびました。

ローカルLLMは、単なる「しゃべるローディングアイコン」として使われているだけではないだろうか、と。
そこから、AIとの対話における「先読み」の難しさと、その先にある未来のガジェット像について、つらつらと考えてみました。
「時間稼ぎ」というUXの限界
「ポケとも」のAI対話システムが採用している「ローカル+クラウド」のハイブリッド方式は、いわば「受付係」と「専門家」の分業体制です。
まず受付係(ローカルLLM)が「少々お待ちくださいね」と場を繋ぐ。その間に奥にいる専門家(クラウドLLM)が、複雑な回答を一生懸命に考える。
しかし、この「受付係」は、奥の「専門家」が今何を考えているのかをリアルタイムで把握しているわけではありません。そのため、彼の「えーっと」には実質的な中身がなく、次に続く本題との文脈的な繋がりも希薄です。
ユーザーからすれば、待ち時間そのものが短縮されているわけではなく、単に「無音」が「あいづち」に置き換わっただけ。これでは本当の意味で対話がスムーズになったとは言い難いのが実情です。
なぜAIは「先読み」ができないのか?
人間同士の会話では、相手が話し終える前に「あ、次はこれを言おうとしているな」という予測がリアルタイムで行われています。これをAIで実現するのが難しい理由は、主に3つあると思います。
- 1. 文脈の多義性
-
日本語は特に省略が多く、言葉が最後まで完結して初めて、その意図が確定する場合があります。
- 2. 処理の継ぎ目
-
AIでは「音声を聞く→文字にする→考える→声にする」という各工程が独立しているため、どうしても「計算の隙間」が生まれます。
- 3. 思考の予測不能性
-
人間は会話の途中で突然話題を変えることがあります。AIがいくら先読みをしようとしても、ユーザーが最後に放つ一言で前提がひっくり返ることがあります。
Gemini Liveの「ネイティブ・マルチモーダル」
そんな中、Googleの「Gemini Live」などに実装された新しい技術の登場によって、この「時間稼ぎフェーズ」の短縮が進んでいます。
Gemini Liveが採用しているのは、「ネイティブ・マルチモーダル」というアプローチです。これは、音声をテキストに変換して読み取るのではなく、音声の波形を「そのまま」理解し、音声で直接打ち返します。
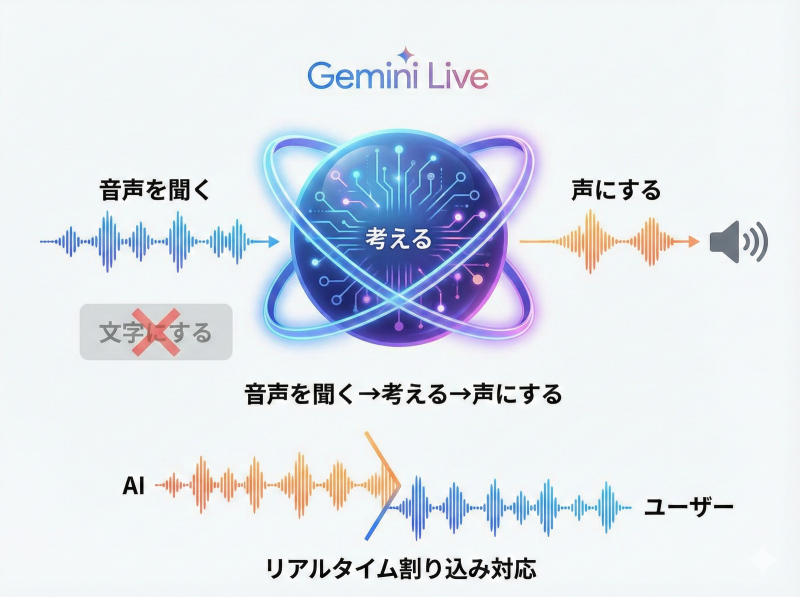
Gemini Liveの中では、「音声を聞く→文字にする→考える→声にする」の4ステップではなく、「音声を聞く→考える→声にする」の3ステップで処理が行われています。
また、Gemini Liveは、AIが話している最中でもユーザーの声を常に監視しており、Gemini Liveの話を途中で遮っても、遮られた瞬間に思考を切り替え、新しい対話を続けることができます。
それでも、意味が確定してから思考を開始する事に変わりはないため、こちらが話している途中で先読み・推測して回答するといったことは、まだ実現できていません。
真の「先読み」を実現するには
では、単なる時間稼ぎではない、本当の意味でスムーズな対話を実現するには、どのような仕様が必要なのでしょうか。私は、次の3つの構造が必要だと考えています。
- 1. 「推測ブランチ」の同時生成
-
ユーザーが話し終えるのを待たず、途中の段階で複数の「回答候補」を裏側で同時に生成し始め、最後の一言を聞いた瞬間に最適なものを出力する仕組み。
- 2. 意味よりも先に「意図」を掴む
-
言葉が確定する前に、声のトーンや速度から「教えたいのか、同意してほしいのか」という「対話のゴール」を先行して解析する専用スキル。
- 3. 「受付係」と「専門家」の同期
-
ローカルLLMがクラウドLLMの「思考の断片」をリアルタイムで受け取り、それを本番の回答へと滑らかに繋がる「助走」として発音し始める仕組み。
私が夢見る「先読みするパートナー」
意味を推測し、意思を先読みし、人間と同じ対話能力を発揮できるようになれば、私が夢見ている、もう一歩先にあるガジェットが実現可能になると期待しています。
空気を読む「アンビエント・オーブ」

デスクに置いておくだけで、自分の動作やこれまでの発言、作業の文脈を学習し、「あれ出して」と言う前に必要な資料をディスプレイに表示。空気感を読み取り、次に必要になりそうな情報を先回りして準備。そんなデバイスがあったら、と想像してしまいます。
私が大好きなSF小説家、神林長平先生の火星シリーズには「PAB(パーソナル人工頭脳)」という球体ガジェットが登場します。常に持ち主と共にあり、その人の思考や行動パターンを学習し続ける人工知性。「俺はお前だ」と言い切る人工知性。まさにそんな存在が、フィクションの世界から現実に降りてくる日が、私が生きている間に来るといいなと思っています。
AIと話してみて気づいた「対話の本質」
今回「ポケとも」を使ってみて、改めて感じたことがあります。
対話において「スムーズさ」とは、単に言葉が途切れないことではなく、自分の意図がリアルタイムで伝わっているという「手応え」感が大事なんだなと。
そのためには、話している途中で「ちゃんと伝わっているな」と感じられることが、実はとても大切なんだなと。
単に「ふむふむ」とレスポンスすればいいというわけではない。「えーっと」と言いながら、実は何も考えていない、それでは、AIガジェットと同じ。
よく、対話の本質は「傾聴」にある、と言われます。それも、単に相槌を打って聞けば良いというものではなく、非常に高度なコミュニケーションの「技術」なんだ、ということを改めて考える良い機会になりました。